再也不说一次打包(Docker),到处部署了。
1. Design
收集需求,拆分需求,保留预算,编写需求说明书(BRD),制作HLS,同时绘制了一套UI(使用Figma)。但是因为种种原因,预算失效。只能自己下场编写。
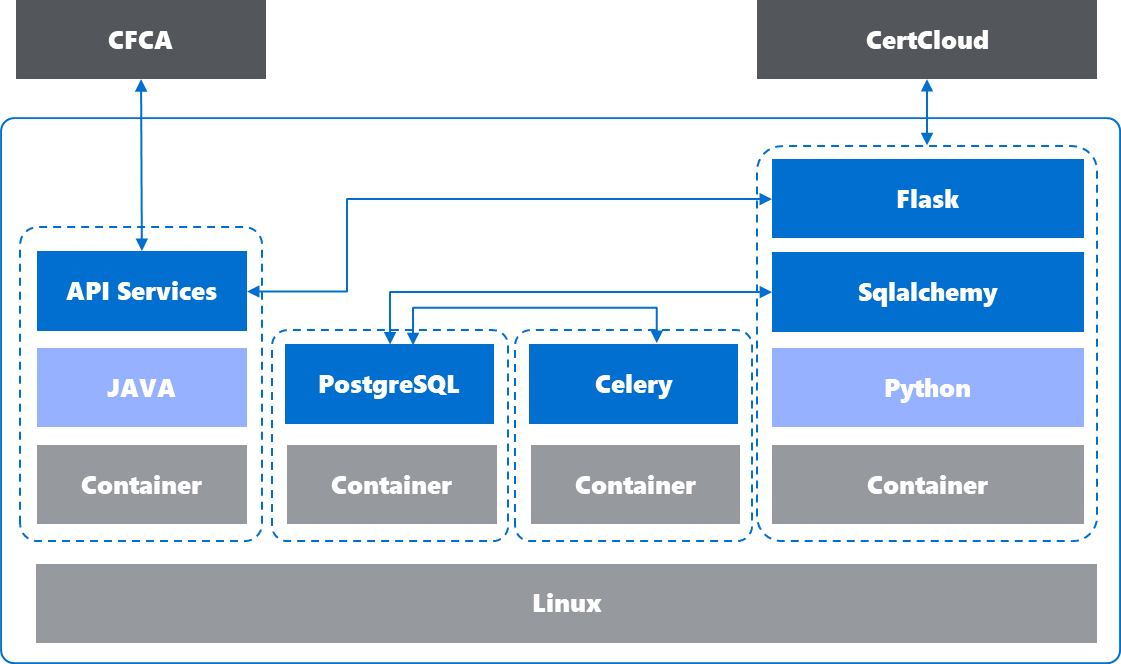
因为需要自己编写,所以需要重新设计研发里的技术架构,我这里选型是以python技术栈,采用flask提供web服务。通过celery提供异步调度的任务。但由于CFCA平台只有Java SDK,所以需要重新wrap业务流程为API服务。同时,需要从flask调用该API Services。链接数据库采用ORM框架,便于测试和迁移。测试开发时选择Sqlite,生产部署时选择Postgres。
前端的结构拆分并没有画,主要包含User Panel, Key Management Panel, Certificates Management Panel,Crypto Box Panel,Financial Panel等,每个Panel里面是list of key/certificate, 之后顶部为search box。点进每个list的item里,可以进入详情页,管理操作等。
2. Build Infra
因为公司内的资源申请流程复杂,也不能使用AI,同时我这个平台的设计不涉及到公司内部平台的数据。于是自掏腰包,通过Google云来搭建一套基础设施。出于编码需求,直接选择了Code Server作为IDE,便于随时随地编辑。之所以选择GCP是因为之前都是用AWS和Azure、Aliyun,而且早年用GCP体验不好,导致放弃了。最近重新捡起来对GCP的学习,因此也把这一套搭建在了GCP上。
- Code-Server Host On GCP Compute Engine
- Casdoor on Docker
- Nginx on VM
// 中间还用Cloud Run和Cloud Build搭建了一个微服务应用。值得一提的是在GCP在设计上给用户的安全感是要强于其他云的。这也印正了早年被面试时问到的一个问题,如何让用户觉得你的产品是安全的,只有在GCP上体验到了。无论是创建Compute Engine时,还是解析绑定DNS给Cloud Run用时,都有一种感觉,平台在帮你做一些默认安全的事情。这一点值得称赞。
其他需要使用到的工具
- Cloudflare (DNS Management & CDN)
- Gemini Chat / Gemini Code Assistant / Gemini Studio API Key
注意: 这里有个问题就是Code Server不支持多用户。
3. Development & Testing
从方法论上推荐TDD,测试驱动开发,这样确保一个小的单元内的代码没有太多错误。具体怎么实现就不多赘述,参考之前总结的软件工程实践:以Python为例, 尤其是AI编程下更高的部分。
不过这里还是会提一下关于配置分离方面的实现。(其实是因为踩了一些坑)
关于配置分离
文件目录结构
├── cfca |
通过start.sh传参的形式,实现生产环境或配置环境的服务启动,例如 ./start.sh dev 或 ./start.sh prod, 命令执行后会分别会去读取对应的文件,例如docker-compose.prod.yml或docker-compose.dev.yml 。以下为start.sh内容和docker-compose.yaml文件
|
之后根据docker compose文件去加载对应的参数
services: |
然后config.py 会根据 crypto_env去加载对应的settings文件, 例如settings.prod.yml或者setting.dev.yml
# settings.dev.yml |
# -*- coding: utf-8 -*- |
最后在app.py里面调用config.py导入配置。
from config import settings |
另外值得一提的是,最开始采用了单文件存两份环境的变量,但导致了环境变量覆盖(不过更可能是没有设计好)。还有一点就是因为Sqlite是文件型数据库,Celery和Flask都会读写该数据库,但由于Celery和Flask是运行的两个容器,通过共享Volume挂载的形式读取到的Sqlite的文件,导致出现了锁的问题,而由于没处理好锁的话,便会一直出现报错。
4. Deployment
部署实际是我与工单不得不说的故事,当然这不是意味着设计的流程和工单非常严谨。而是说明了在金融企业里,大家习惯了沉闷,把慢的离谱的手动的流程都当作是一种可以接受的合理的合规的存在。另外就是因为快速迭代并不是这里的优先级,稳定才是。所以更加导致了流程和制度的层层加码。即便应该使用更好的方法去实现控制。就像之前提到过的实现安全的纵深防御,但不是重复防御一样的道理。这么多工单,真的是有必要的吗?
工单举例(仅我能想起来的,中间有的要开几遍):
- VM的申请
- 堡垒机的访问权限申请
- 特权账户的申请
- 防火墙的开通(我的IP向平台开通访问;向办公网开通访问;平台允许我的IP等)
- 防火墙的例外申请及记录
- 服务邮箱的申请
- 申请域名
- 申请DNS解析
- 申请企业CA签发的证书
还不包含以下等等
- 代码的扫描
- 容器的扫描
- 托管密钥的申请
- 内部SSO的集成
- SIEM的集成
看到这里,我在想如果我是一个研发,可能我也要骂DevSecOps。如果不是经历了一遍研发设计和部署,那么这些安全控制的东西可能还会令人沾沾自喜。但实际看下来,则是非常影响研发效率的。但快速迭代和安全之间一定是要取得一个平衡的,如何实现,值得思考。
5. Issues
这里记录一下,从研发之初到部署时遇到的过的Bug,以及如何解决的。
工具或平台(Platform)类:
- A平台页面触发的申请动作会触发平台侧邮箱通知,但api申请则不触发。那只能自己实现邮箱通知的功能
- A平台测试环境IP:PORT使用443, URL使用9443,但却仅告知了开防火墙443,排错时才发现9443也存在通讯。但在迁移到生产时,直接更换了URL中的IP之后,又发现生产只访问URL且使用443端口
- A平台测试环境的登陆证书下载后,平台侧未同步,导致访问失败
- A平台生产环境登陆证书转JKS格式后未添加OCA1的证书链接导致NO Trust Store
- B平台的API文档里的传参和实际传参不一致。 报错信息几乎为0。 {K:[V]} 不是 {K:V}, 有的传string of list但不是传string。换了最新版的文档就解决了
关于Docker/Podman:
- 即便号称Podman和Docker兼容,且默认Rocky上是安装的Podman,但Docker Save的Image在Podman Load之后无法完全正常运行。(需要深入了解才行)
- 【开发时】Windows平台中Dockerfailed to solve: failed to read dockerfile: open /var/lib/docker/tmp/buildkit-mount770356576/Dockerfile: no such file or directory, 采用
cd "C:\Program Files\Docker\Docker" && ./DockerCli.exe -SwitchLinuxEngine的形式进行修复 - 【开发时】打包java为镜像后,运行时显示无法找到main class。原来是因为
COPY --from=builder /app/target/*.jar /app/application.jar,实际需要copy一个指定的jar即可,指定jar拷贝进去即可生效。即便target下面只有一个jar包。 - 【开发时】Compute Engine的Disk空间不足。
docker system prune -a -f && docker volume prune -f可以释放部分空间,但是不如挂载新的盘。 - 【开发时】无法保存CASDoor的配置,因为Disk Space不足
- 【开发时】使用docker-compose文件打包时,本地镜像缺失但无法拉取,已经docker login过。后直接单独拉取镜像后,docker compose build则正常。
OS的版本,测试时用的Ubuntu, 部署时用的Rocky。另外现在用docker compose不用docker-compose了。另外部署时(Rocky8 Linux)遇到的dockers问题,开发时(Ubuntu Linux)一次也没遇到过。
- 【部署时】rocky 默认使用podman,需要单独配置镜像才能安装docker-ce
- 【部署时】docker load/save 和 import/export不一致。需要保证全layer。 podman不支持import
- 【部署时】ubuntu上的docker compose起来的postgresql直接可以用,rocky上 的docker compose起不来postgresql
- 【部署时】使用network可以内部链接,但通过服务名无法寻址。
- 【部署时】Nginx反代无法访问到docker暴露的本地端口,需要指定容器IP。可能是firewalld导致的
- 【部署时】使用暴露端口到本地时,应用内无法访问127.0.0.1:port
- 【部署时】容器起不来直接崩溃退出,默认ENTRYPOINT是执行java程序,可以传参给entrypoint给docker以便进入容器排错。
docker run --entrypoint /bin/bash cfca-api - 【部署时】Docker的Service不能靠Service Name寻找到,增加Docker Network配置即可。在docker-compose文件中全部设为同一个network
- 【部署时】起容器时load本地的文件,但权限不对,无法打开。
- 【部署时】申请的公司内部的smtp邮箱登录是按照域账号,不是邮箱账户作为用户名。
- 【部署时】设计了nginx作为reverse proxy,但SSO的callback里填的是http,导致nginx完成SSO认证之后(https)跳回了http,访问失败。解决方案就是将nginx http都重定向为https。当然,更应该在SSO的callback的里填写https的链接。同样的还有一个安全问题,就是把127.0.0.1的测试用的callback去掉。
- 【部署时】docker compose文件正常能够启动postgres,但是rocky上起来之后,显示缺乏pg_hba.conf文件,增加之后,重新启动则显示password authentication失败,进入容器排查,发现无对应用户。创建无法实现,通过init.sql在创建时也不生效。最后单独启动postgre并传入命令行参数可以生效。具体原因未知。
Windows:
- celery在windows平台和linux平台下运行的不一致,参数不同要加
-P evenlet,否则终端会假死。celery -A tasks.celery_app worker -l info -P eventlet因为默认实现的prefork不兼容,fork()函数的系统调用是在linux下的。 但同时要注意, celery的beat功能不支持-P eventlet - 使用pipreqs生成依赖时显示编码问题,强制使用utf-8解决,
pipreqs . --force --encoding utf-8
编码(Coding/Programing)类:
- application读jks文件路径不对,测试时和打包后不一致。
- print到stdout但是不显示,更换使用logging模块显示
- celery 调度任务失败了,但是状态被记录了。即便后续重启任务,状态不会被刷新。(不知道为啥)
人为疏忽类:
- 单词拼写错误,xxxxservice vs xxxxservices ; orgnization vs organization
- 两侧都要开防火墙: 机房出网要开防火墙,访问对方端点要加机房的出口IP。 然后防火墙说开通了,实际测试不通。因为还有一条deny all的策略。
- 配置分离后,填入了平台正确的生产环境Token,结果显示未认证。检查发现,平台侧创建后未启用该Token
AI类:
- 删除了不该删除的代码,逻辑改变,疯狂报错
- 增加了不该增加的特性,页面逻辑改变
- 为Docker Compose file优化时增加了Health Check,然后该服务本身没提供healthcheck端点,且之后有服务依赖该容器起来,导致接连启动失败。
6. Conclusion
先看AI,在整个研发过程(业余耗时2月)中。AI体现出了无比高效率的编码和排错思路,尤其在前端代码的编写上。让人非常舒服的同时也暴露了一个问题,那就是只会对AI提问但不会动脑的话自己也会降智。
再看部署,对Docker的一处build处处运行过于自信。以至于预估的一天内部署完成,实际花了3天左右的时间。
再回到安全,从研发而言来看DevSecOps对技术的成熟度和研发人员素质的要求确实有点高了。企业里连devops的人员能力都没有,还谈DevSecOps,痴人说梦。
最后不得不说,最不安全的就是做安全的,一点不假了。
最后的最后,一些技能真的是时间久了不用就忘。所以熟能生巧又何尝不是一种本领。